

The Business Analytics Institute will once again be hosting its Summer School in Data Science for Management in Bayonne, France from July 2 to 11 2018. In this exclusive five-part series on Why Future Managers Should Invest in Data Science, we will explore the BAI’s unique value proposition around improving managerial decision-making.
Early this month, president Emmanuel Macron pledged to make France a major international hub of Artificial Intelligence.The French government has committed €1.5 billion over five years to support research in the field, encourage startups, and collect data that can be used safely by organizations and individuals alike. With all the buzz concerning artificial intelligence, machine learning, and deep learning what exactly is the vision and value of each? More importantly, what can you learn about AI from the BAI in general, and our Summer School in particular?
What do we mean by Artificial Intelligence?
Coined by John McCarthy over sixty year ago, the term Artificial Intelligence refers to the ability of information technology to perform tasks commonly associated with human reasoning. Data scientists feed the development of AI through the identification of pertinent and meaningful information in both small and Big Data sets. Despite the hype, current implementations of AI are limited to “Narrow AI” – which concerns a computer program capable of performing a particular task well (Chess, image recognition, translations, sales predictions…).
Discussions of “General AI” which refer to a machine’s ability to do perform a wide variety of tasks as well or better than its human counterparts are still science fiction – “robots” won’t be replacing managers any time soon. Finally, the concept of “Super AI” first introduced by Nick Bostrom, suggests algorithms capable of redefining the problems we are trying to solve – an idea that is unfortunately as intriguing as it is unreachable today. Machine learning, deep learning, and process mining are all approaches to implementing artificial intelligence
What exactly is Machine Learning
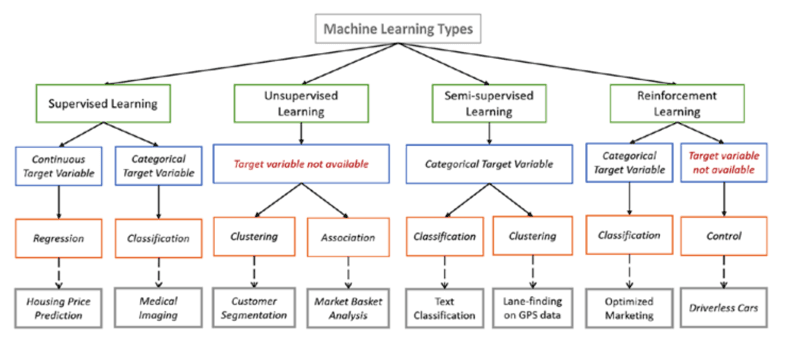
Machine learning refers to computer programs that can learn from the data set with which it is associated. Machine learning involves training an algorithm to identify relationships in the data without having to explicitly program all the potential cases and outcomes. There are four main categories of machine learning: supervised (in which the data includes “labels” indicating the relative importance of its attributes), unsupervised (involving “raw” unclassified data), semi-supervised (including both labeled and unlabeled data) and reinforced (which trains algorithms using a reward system). Within each category, data scientists work with a number of methodologies and models including regression, clustering, Bayesian networks, support vector machines, and random forest.
Each methodology incorporates a set of classifiers that the computer understands (the notion of representation), a scoring function (for evaluation) and a search method (for optimization). The choice of the methodology depends on the nature of the problem “environment” under study (deterministic or stochastic), the quality of the data (nominal, ordinal, ratio, structured, unstructured…), and the model’s parameters (the assumed properties of the data imposed by the model, the training data, and the problem at hand). In each case the machine “learns” as the pertinence and the efficiency of the algorithm is adjusted to the properties of the data.
What is the difference between Machine Learning and Deep Learning?
Deep learning is one specific approach to machine learning. Deep learning involves the study and design of machine algorithms to produce better representations of the data at multiple levels of abstraction. Deep learning mimics the structure and functions of our own brain, involving how neurons, nerve fibers, and synapses interact to process information in the hippocampus. Artificial Neural Networks (ANNs) are algorithms in which “neurons” have discrete layers and connections to other “neurons”. Each layer picks out a specific feature to learn, such as curves/edges in image recognition. It’s this layering that gives deep learning its name, depth is created by using multiple layers as opposed to a single layer.
Most deep learning algorithms today are based on the principles of backpropagation and propose architectures such as deep neural , deep belief and recurrent neural networks The advantages of deep learning are its scalability (the ability to work increasingly quicker with larger quantities of data and more complex models,) and its flexibility–(the ability to perform automatic feature extraction from raw data). Over the last thirty years, successful implementations of deep learning have been documented in speech recognition, computer vision, natural language processing, and social network filtering. Current applications of deep learning are focusing on domains like personalized healthcare, robot reinforcement learning, and sentiment analysis. Current challenges in deep learning include its time and cost, overfitting the model, unsupervised learning especially with small data sets, and simulation-based learning.
Why invest in Process Mining?
Process Mining provides a bridge between Data Science and Digital Strategy by using the available data to improve how organizations work. Process Mining employs machine learning to automate the discovery, design, and improvement of how information flows between an organization, its customers, and suppliers. In comparison with other fields in Data Science, the goal here is to go beyond studying the nature of organizational challenges to designing more effective business processes and networks. As an integral part of Digital Strategy, process mining helps organizations understand their data collection and processing needs, and ultimately the worth of their data.
Process mining is used today in the fields of operations management, service design and delivery, customer relationship management, and supply chain modeling. Concretely, process mining incorporates machine learning algorithms to analyze business processes based on event logs. During process mining, data scientists apply AI techniques to training data to identify trends, patterns and details contained in event logs recorded in an organization’s ERP, CRM, or legacy systems. Process Discovery suggests modeling new processes or networks based on the data of low-level events. Conformance checking involves exploring the discrepancies between the data and the organization’s vision of its existing processes, procedures, and networks. Performance mining refers to prescriptive solutions of how to improve organizational performance with respect to specific process performance measures.
Human and not just Artificial Intelligence
As promising as Artificial Intelligence appears, AI is a tool rather than a solution to address deeply rooted problems in business and society. “The goal of data science isn’t to make machines smarter, but to help people take better decisions. No matter how far the scientific community can take AI in the years to come– the best algorithms will be no better than our own ability to design and apply them. The business value of data science isn’t dependent upon the quantity and quality of the data, but upon how an organization’s managers, business partners and customers are in using the data to explore and enrich the relationships between people, technologies, and organizations.
“The first challenge of Artificial Intelligence is that of human talent” – Emmanual Macron
The Business Analytics Institute structures its work around a vison of Analytics 4.0. In a world increasingly permeated by IoT, machine learning, and technology, our end goal isn’t to make machines more intelligent, but to help people take better decisions. Adressing Human Intelligence, and not just AI, Analytics 4.0 is a call to action designed to transform the abundance of data at our disposal into actionable, measurable strategies for improving how organizations work. Analytics 4.0 is built upon four pillars: understanding the role of data in modern economies, examining the cognitive processes intimately tied to human decision-making, applying machine-learning given the types of problems we are trying to solve, and transforming data into actionable decisions.
The BAI Summer School on Data Science for Management
Using real-life examples and case studies in the health and life sciences, participants in this year’s BAI Summer School will discuss the managerial applications of Artificial Intelligence. You will examine how Little and Big Data sets can be used to improve individual and organizational decision-making. You will apply the models and tools for creating, collecting, and codifying organizational information. You will learn how to choose and apply the appropriate decision models based on the challenges at hand. You will explore how Process Mining can enhance decision-making by converting data into actionable insights. Finally, you will analyze the ethical issues inherent in data-driven decision-making.
————————————————————
Yann Gourvennec a créé visionarymarketing.com en 1996. Il est conférencier et auteur de 6 livres. En 2014, il est passé d'intrapreneur à entrepreneur en créant son agence de marketing numérique.
- Multicloud Synchronisation: Onecloud, Google Cloud and others - 25/04/2024
- Perceptron: A History of Neural Networks - 22/04/2024
- Networking and Growing Your B2B Business with LinkedIn - 20/04/2024


